
")
שירים יד מי שמעולם לא חיפש את שמו בגוגל. איתור אדם באמצעות שמו היא פעולה שגרתית המתבצעת כיום באינטרנט, כמו חברות שמחפשות מידע במנועי החיפוש על מועמדים לעבודה, אנשים שמבקשים לאתר קרובי משפחה או חברים מהעבר ועוד.
אחת הבעיות בחיפוש שמות, באנגלית לפחות, נובעת מהעובדה שבניגוד למילה כללית, כמו המילה "כדור", שיש לה דרך אחת ויחידה להיכתב, ישנן מספר דרכים אפשריות ולגיטימיות לכתוב שמות פרטיים ושמות משפחה. למשל, Victor ו-Viktor, Sofia ו-Sophia ועוד.
על מנת להתמודד עם הבעיה, ד"ר מיכאל פייר, ד"ר רמי פוזיס והדוקטורנט אביעד אלישר מהמחלקה להנדסת מערכות תוכנה ומידע באוניברסיטת בן-גוריון בנגב, פיתחו צמד אלגוריתמים פורצי דרך בתחום אחזור השמות, המנסים לפתור את הבעיה משתי זוויות שונות.
האלגוריתם הראשון שנקרא (GRAFT)- GRAph based on names derived from digitized Family Trees מנצל מידע היסטורי שנאסף מאתרים גנאלוגיים (אתרים של שושלות יוחסין), בשילוב עם אלגוריתמים מעולם הרשתות (Network Science). "אם רואים, למשל, לאורך ההיסטוריה, שהיה סבא משה ולנכד שלו קוראים מושיקו, אז יכול להיות שיש קשר בין השמות, מושיקו נקרא על שם הסבא ולכן גם איות השם שלהם יהיה זהה", מסביר אלישר ל-mako.
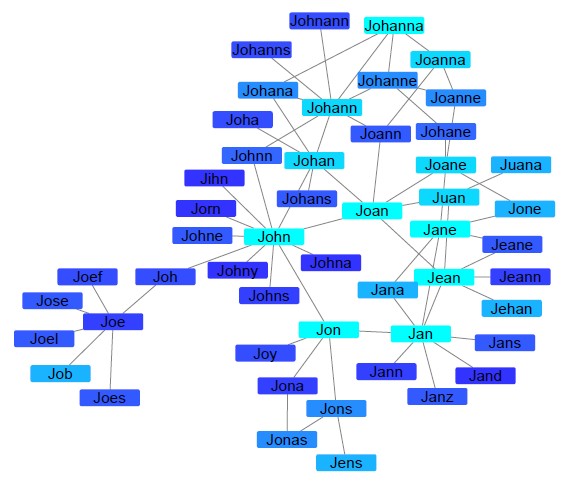
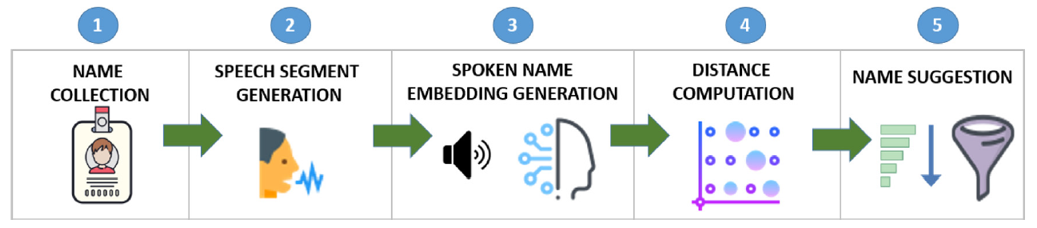
האלגוריתם השני נקרא SpokenName2Vec. בניגוד לאלגוריתם הראשון, המנצל תבניות לאורך שושלות היסטוריות על מנת להציע שמות נרדפים, אלגוריתם זה מנסה לפתור את הבעיה תוך שימוש בקול אוטומטי ולמידה עמוקה (Deep Learning). שהרי שמות דומים אומנם נכתבים שונה, אך נשמעים דומה (למשל Victor ו-Viktor, Elisabeth ו-Elizabet).
במקרה זה, הציעו החוקרים ייצוג חדשני ופורץ דרך לשמות, אשר לוקח בחשבון את הצורה בה בני אדם מבטאים את השם בשפה מסוימת ובמבטא מסוים. ייצוג זה מאוד דינמי ומאפשר לזהות שמות שנהגים בצורה דומה, אך לאו דווקא נכתבים באותה הצורה.
"הרעיון למחקר עלה כאשר אחד המנחים חיפש חברת עבר מארה"ב, כדי לשאול לשלומה, אבל מצא שיש הרבה דרכים לכתוב את השם שלה", מספר אלישר. "הוא הצליח למצוא אותה בסוף, אבל עבד קשה. בנוסף, אני מאוד אוהב שמות באופן כללי – את ההיסטוריה של השם, איך הוא התגלגל ומה המשמעות שלו. מבחינתי זה היה שילוב מאוד כיפי עבור הדוקטורט שלי".
")
")
"גם העובדה שלמיקי (ד"ר מיכאל פייר – ד.ג) היו נתונים מתאימים, דאטה בייס של עצי משפחה, עזרה לנו. ביחד זה היה טריגר להתחיל לעבוד על המחקר", מוסיף פוזיס.
השיטות שפיתחו החוקרים נבנו על סמך מקור מידע עצום הכולל כ-17 מיליון בני אדם, ומכיל בתוכו מעל ל-700,000 שמות פרטים ו-500,000 שמות משפחה ייחודים. האלגוריתמים המוצעים הציגו עליונות מובהקת באיתור השמות ופורסמו בכתבי העת היוקרתיים – IEEE Transactions on Knowledge and Data Engineering ו-Knowledge-Based Systems.
החוקרים מדגישים כי המחקר נעשה על שמות באנגלית, שם קיים קושי גדול יותר לאיית שמות, אבל היו שמחים אם היו מנסים אותו גם על שמות בעברית. ויש גם בשורה לציבור הרחב: "סטודנטים מתואר ראשון עובדים על אתר שינגיש לקהל את האלגוריתמים שפיתחנו", מספר פוזיס. "זה פרויקט הגמר שלהם, אז הצפי שהאתר יהיה מוכן בסוף השנה האקדמית, אם לא יהיו הפתעות".
ואם בגוגל ירצו להשתמש במידע? "אנחנו נשמח", אומר פוזיס.